Compositional Convolutional Neural Networks: A Deep Architecture with Innate Robustness to Partial Occlusion#
Authors: Adam Kortylewski, Ju He, Qing Liu, Alan Yuille
Affiliations: Johns Hopkins University
CVPR, 2020
Links: arXiv, thecvf.com
Summary#
Recent findings show that deep convolutional neural networks (DCNNs) do not generalize well under partial occlusion. The authors propose to integrate compositional models and DCNNs into a unified deep model with innate robustness to partial occlusion, termed Compositional CNN.
Results show that DCNNs do not classify occluded objects robustly, even when trained with data that is strongly augmented with partial occlusions. The proposed model, CompositionalNets, outperforms standard DNNs by a wide margin at classifying partially occluded objects, even when it has not been exposed to occluded objects during training.
Key Ideas#
Fully generative compositional models. Let \(F^l \in \mathbb{R}^{H \times W \times D}\) be the output of a layer \(l\) in a DCNN. The authors proposed a differentiable generative compositional model of the feature activations \(p(F \mid y)\) for an object class \(y\), which is modeled as a mixture of von-Mises-Fisher (vMF) distributions:
where \(\theta_k = \{ \mathcal{A}_y, \Lambda\}\) are the model parameters and \(\mathcal{A}_y = \{\mathcal{A}_{p, y}\}\) are the parameters of the mixture models at every position \(p \in \mathcal{P}\) on the 2D lattice. In particular, \(\mathcal{A}_{p, y} = \{\alpha_{p,0,y}, \dots, \alpha_{p, K, y} \mid \sum_{k=0}^K \alpha_{p, k, y} = 1\}\) are the mixture coefficients and \(\Lambda = \{\lambda_k = \{\sigma_k, \mu_k\} \mid k = 1, \dots, K\}\) are the parameters of the vMF distribution:
where \(Z(\sigma_k)\) is the normalization constant.
Occlusion reasoning. Compositional models can be augmented with an occlusion model at each position \(p\), either the object model \(p(f_p \mid \mathcal{A}_{p, y}^m, \Lambda)\) or the occluder model \(p(f_p \mid \beta, \Lambda)\) is active:
where \(\mathcal{Z}^m = \{z_p^m \in \{0, 1\} \mid p \in \mathcal{P}\}\).
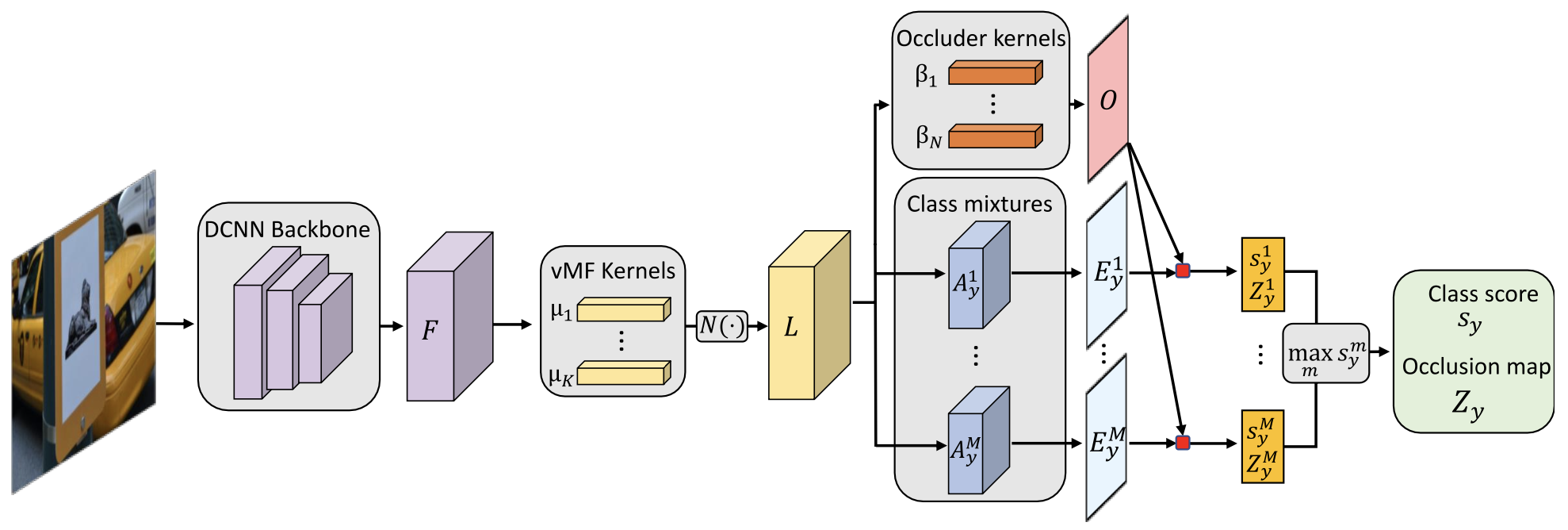
Figure 1: Feed-forward inference with a CompositionalNet.#
Technical Details#
Inference as feed-forward neural network. The computational graph of the fully generative compositional model is directed and acyclic, and can be inferenced with a single forward pass.
End-to-end training of CompositionalNets. The model is fully differentiable and can be trained end-to-end using backpropagation. The loss function is composed of four terms
where \(\mathcal{L}_\text{class}\) is the cross-entropy loss between the network output \(y'\) and the true class label \(y\), \(\mathcal{L}_\text{weight}\) is the weight regularization on the DCNN parameters, \(\mathcal{L}_\text{vmf}\) and \(\mathcal{L}_\text{mix}\) regularize the parameters of the compositional model to have maximum likelihood for the features in \(F\).
Classification results for vehicles of PASCAL3D+ with different levels of artificial occlusion.
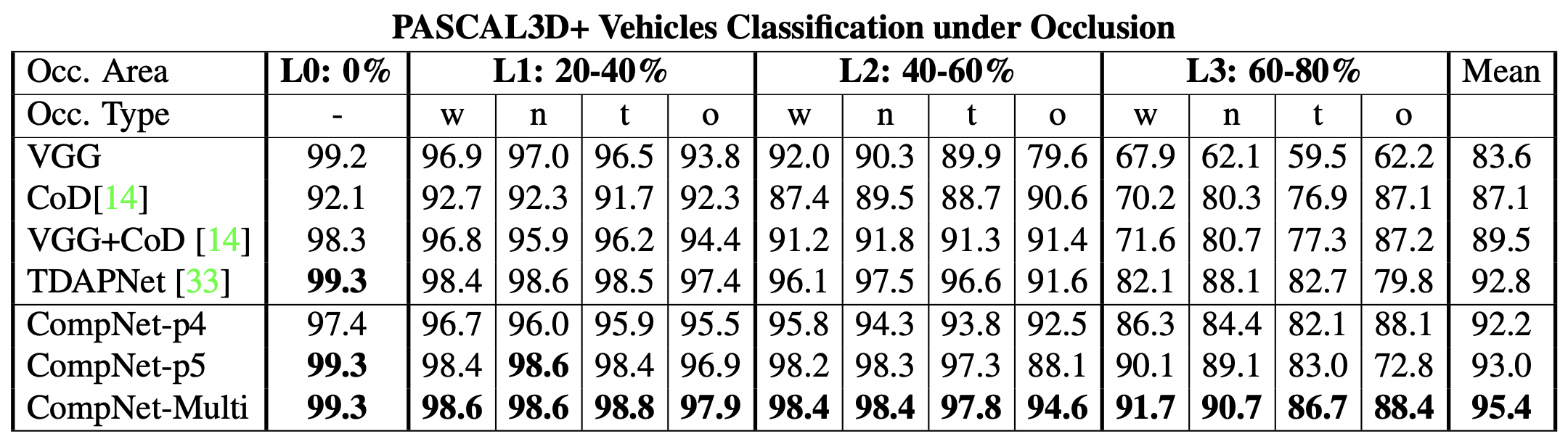
Figure 2: Classification results for vehicles of PASCAL3D+ with different levels of artificial occlusion.#
Classification results for vehicles of MS-COCO with different levels of real occlusion.
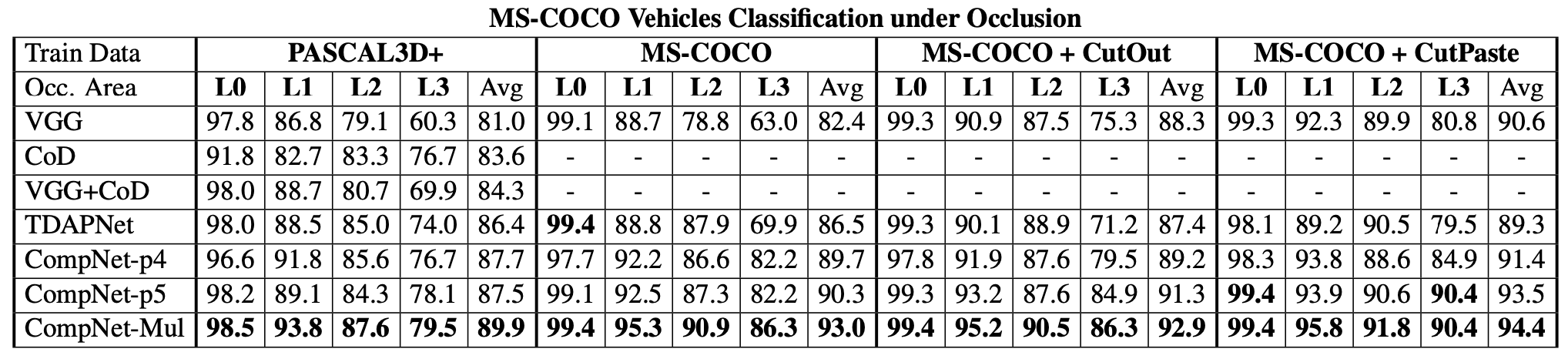
Figure 3: Classification results for vehicles of MS-COCO with different levels of real occlusion.#
Occlusion localization results.
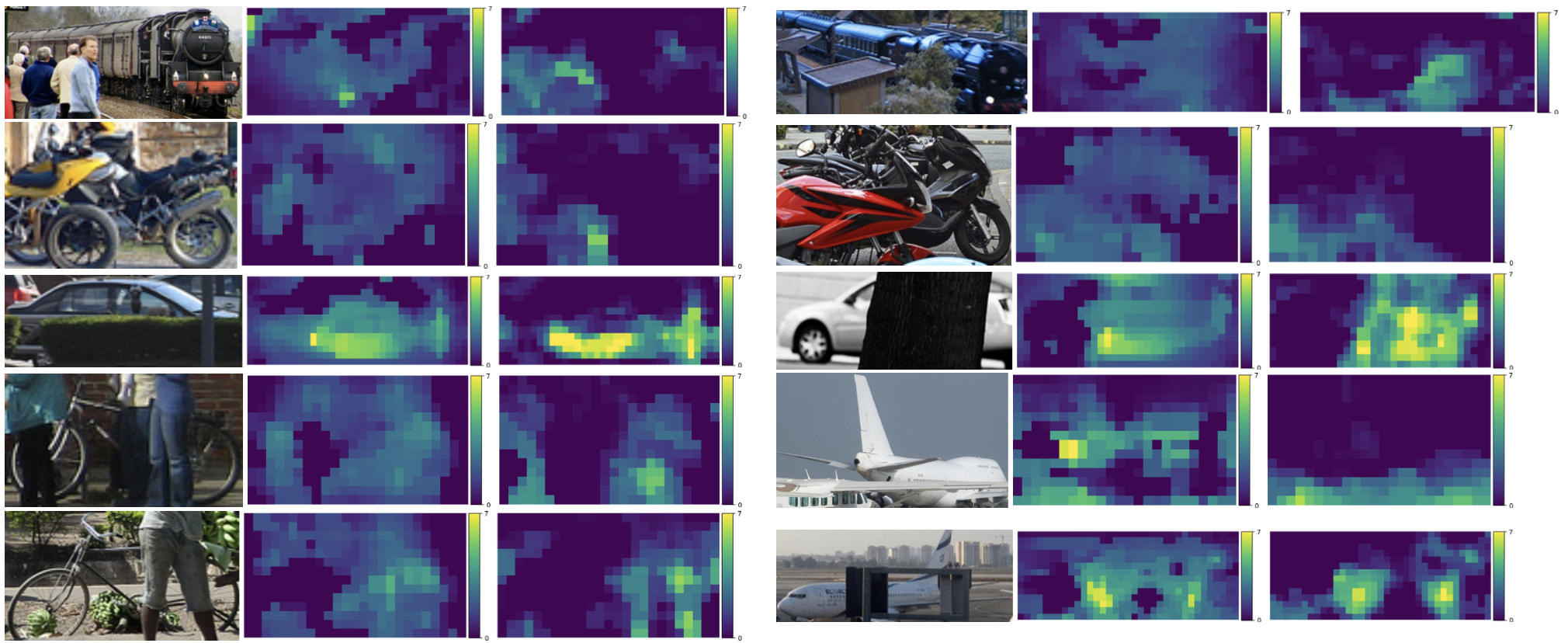
Figure 4: Occlusion localization results.#
Notes#
References#
[1] A. Kortylewski, J. He, Q. Liu, A. Yuille. “Compositional convolutional neural networks: A deep architecture with innate robustness to partial occlusion.”. In CVPR, 2020.